|
I am a final year Ph.D. Candidate (Jan'23 - Dec'26) from Center for Research in Computer Vision (University of Central Florida) under Prof. Yogesh S. Rawat. My research focuses on Noise Robustness, Person Re-Identification (ReID) and efficient Deep Learning. Prior to UCF, I earned my Master’s in Computer Science from New York University (NYU) Courant Institute, where I completed my thesis under the guidance of Prof. Rob Fergus. I hold Dual Bachelor of Technology (B.Tech) degrees in Electrical Engineering and Computer Science from the Indian Institute of Technology (IIT) Kanpur. |

|



|
My research centers around efficient training in computer vision, with a strong emphasis on improving robustness to real world noise, like autonomous driving scenarios of fog, rain, and snow. My primary focus lies in Zero Shot learning and VLMs (transformers) , with a specific emphasis on object detection. I also have substantial experience in interpretable and explainable AI and Visualization, enabling easy to understand insights into models. In parallel, I have been actively working on Person Re Identification (ReID) for the past seven years, which was the core of my Master’s thesis as well. |
|
|
Priyank Pathak, Yogesh S. Rawat PhD Dissertation || Dissertation Proposal 🎙️ YouTube
Noise Robustness
Opening Black Box
OOD
Zero-shot
VLMs
Prompts
|

|
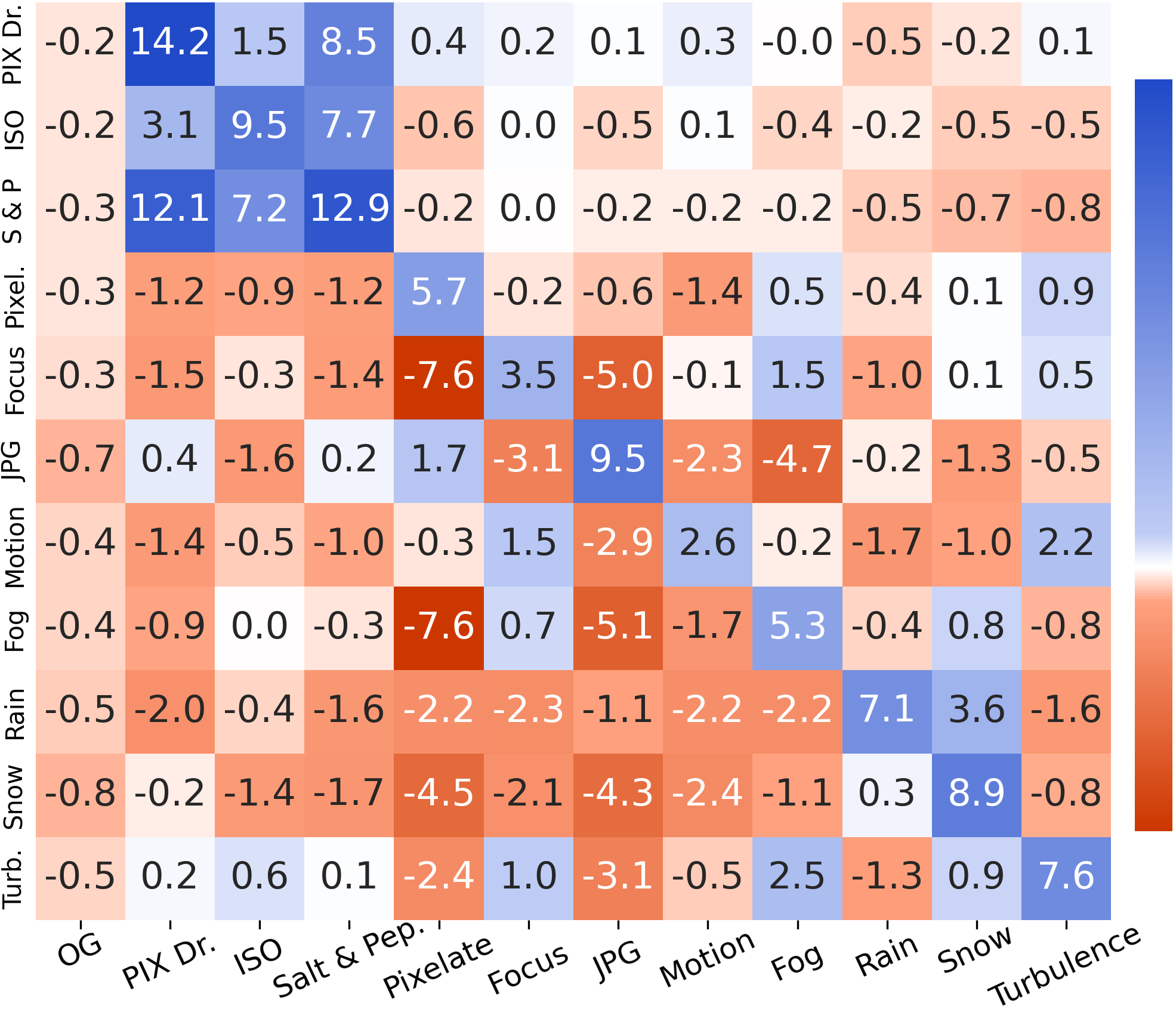
Priyank Pathak*, Mukilan Karuppasamy*, Aaditya Baranwal, * equal contribution ECCV'26 🪧 Paper / Project Page / Code / Arxiv
Noise Robustness
Object Detectors
Zero-shot
Explainable AI
Opening Black Box
Noises
|

|
Shresth Grover, Priyank Pathak, Akash Kumar, Yogesh S Rawat ECCV'26 🪧 Paper / Dataset / Project Page / Code / Arxiv
LLMs
Resoning Technique
Benchmark
Sequence
Error
|
|
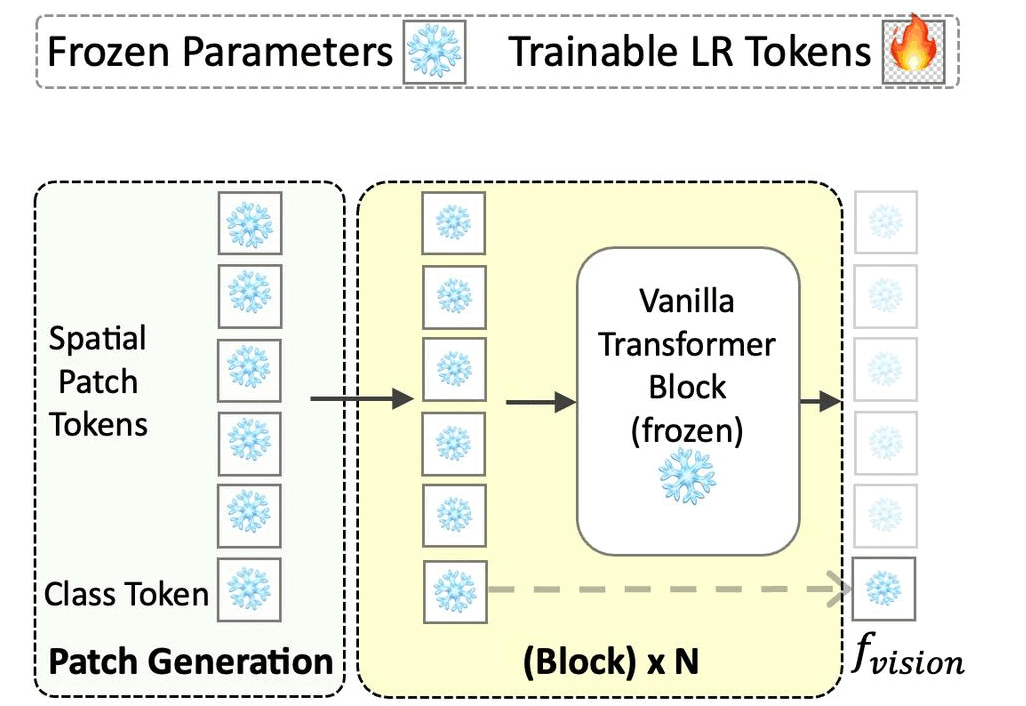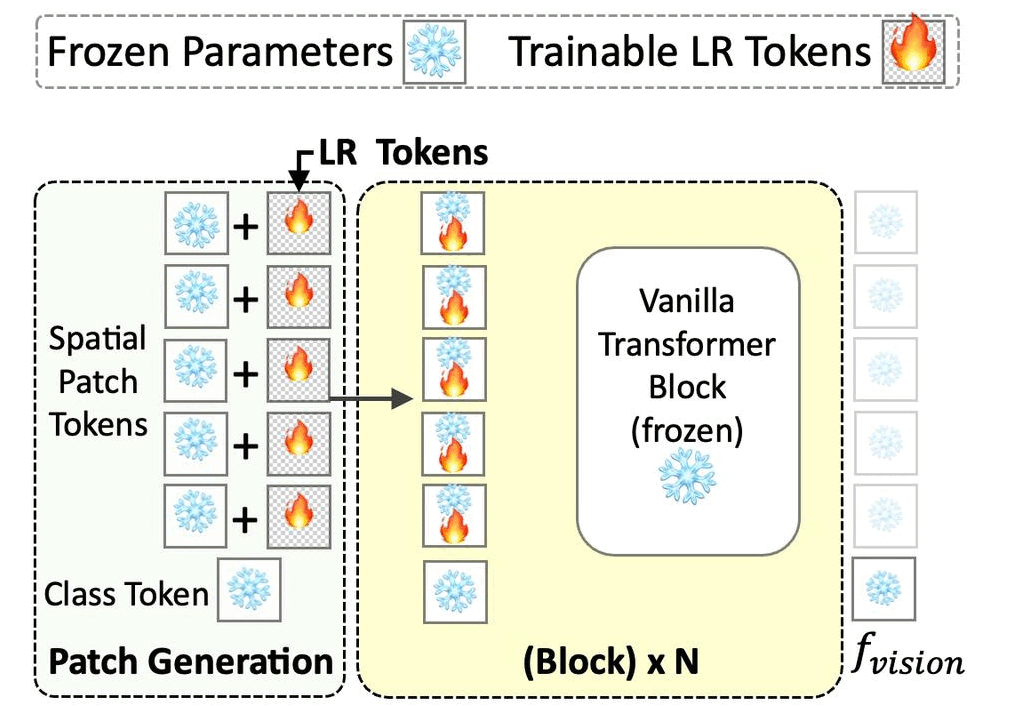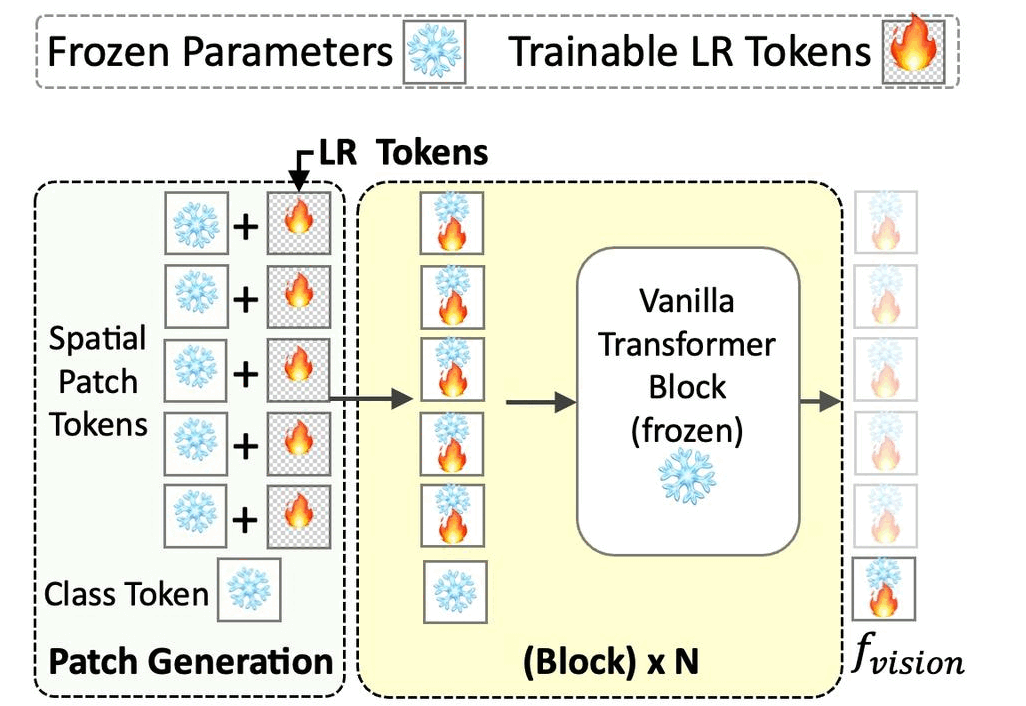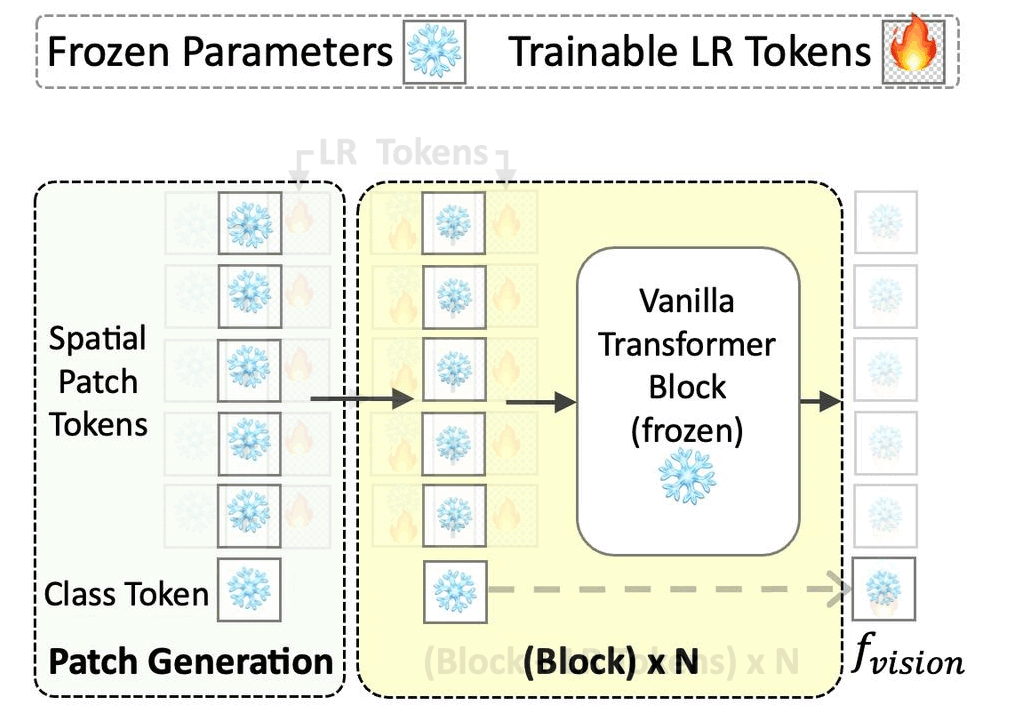
Priyank Pathak, Shyam Marjit, Shruti Vyas, Yogesh S. Rawat ICLR'25 || ICCV'25 (Non-Proceedings) 🎙️ Paper / Project Page / Code / Arxiv
Noise Robustness
Zero-shot Images
VLMs
Prompts
Benchmark
|

|
Priyank Pathak, Yogesh S. Rawat ICCV'25 || Patent filed 📜 Paper / Project Page / Code / Arxiv
Person ReID
Self-Attention
Video & Image
Efficiency
|
|
Priyank Pathak, Yogesh S. Rawat BMVC'25 Paper / Code / Arxiv
Person ReID
Real World
Noisy Images
ResNets
|
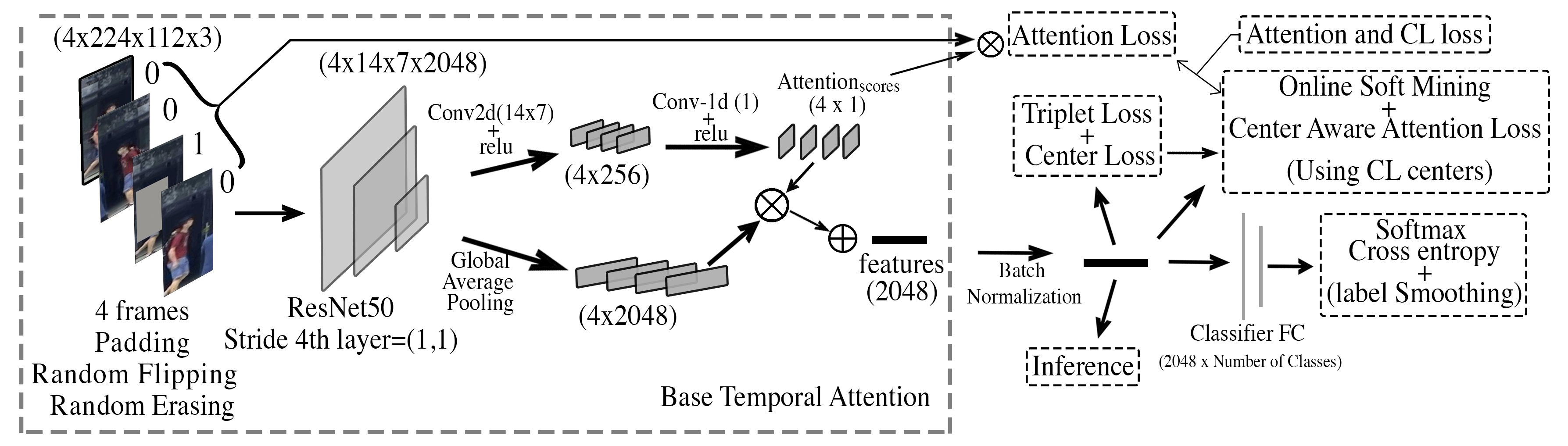
|
Priyank Pathak, Amir Erfan Eshratifar, Michael Gormish AAAI'20 Paper / Code / Arxiv
Person ReID
Video & Image
Techniques
Novel Loss
|
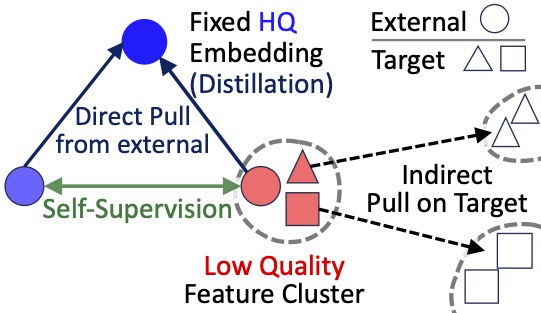
|
Rajat Modi, Xin Liang, Priyank Pathak, Yogesh S Rawat Under Review 🔒
Test Time Training
VLMs
Efficinet
Distillation
Dense Task
|
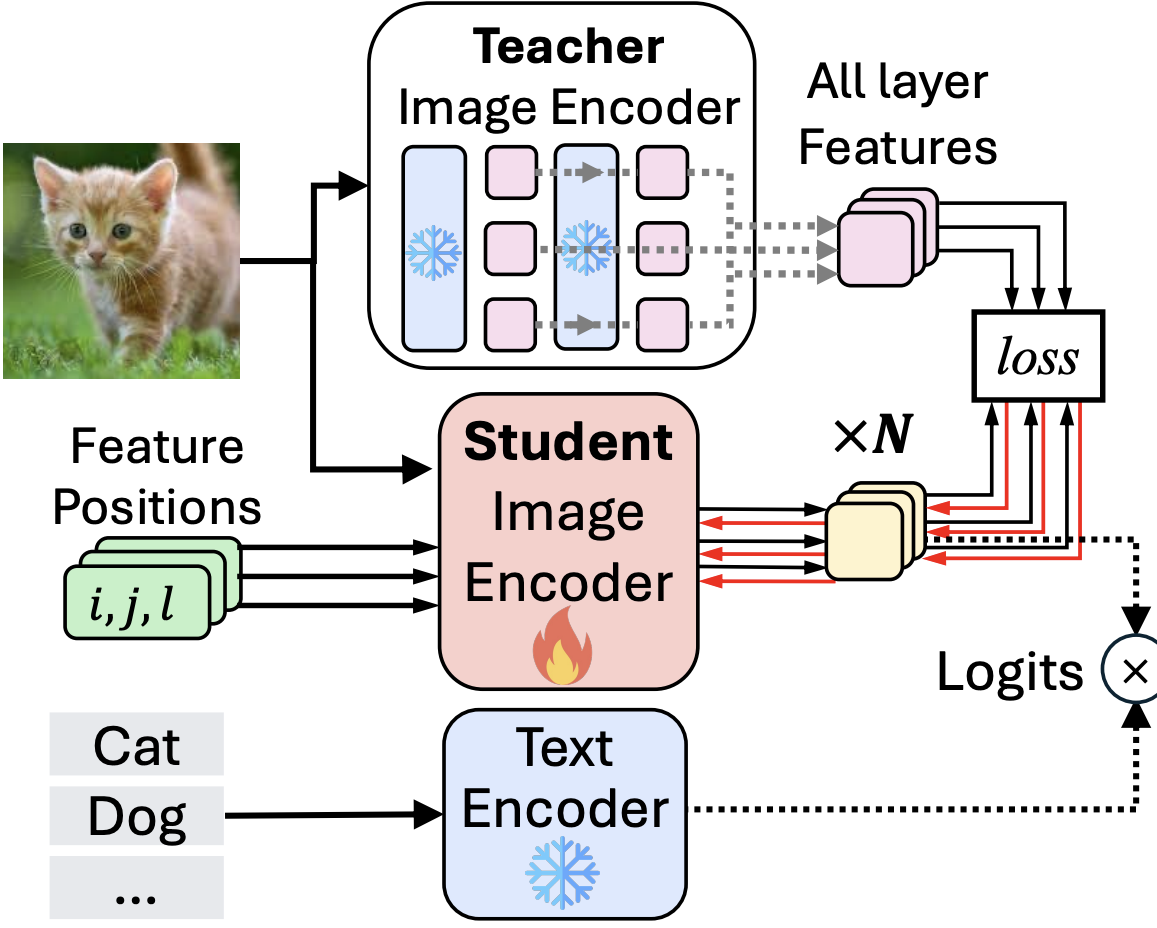
|
Priyank Pathak, Yogesh S Rawat Preprint 🤫
Zero-Shot
VLMs
Object Detectors
Robustness
|
|
|
|
|




|
|
|
|
Reviewer, Neurips 2026 Reviewer, ECCV 2026 Reviewer, CVPR 2026 (Outstanding Reviewer) / (Tweet) Reviewer, ICLR 2026 Reviewer, AAAI 2026 Reviewer, Neurips 2025 Reviewer, BMVC 2025 Reviewer, CVPR 2025 (Outstanding Reviewer) Reviewer, ICLR 2025 (Outstanding Reviewer) |
|
|
Fine-Grained Re-Identification (Master's Thesis) Local Learning on Transformers via Feature Reconstruction |
|
I sometimes open-source implementation of others' papers. |
Success of Filmmaking (JS & Novel Visuals) [Youtube Feature | Online | GIF ]
Beautiful Customizable plots for Research Papers [GitHub] Faster RCNN tutorial [ Githhub] Reinforcement learning tutorial [Web Page] Spatial Transformers for traffic signal detection [Github] Video-Action-Transformer-Network [Github] Online softmining loss [Github] |
{kind=link}
|
"Aloo has no place in Biryani" - Every Desi Foodie Built upon Jon Barron's template, and modified upon Rohit Gupta |